I realized overnight that I had not explained my amazement and delight at the results of your experiment and that I should add a few notes for new readers of this forum, hoping that those readers who already knew about it would not mind it being repeated in this thread. Having this morning seen your post it seems a good idea to add the explanation as a reply.
Since the days of using metal type I have been interested in ligatures.
When I began to learn about electronic fonts I found that although glyphs for ligatures could be added, mapped to the Unicode Private Use Area, that there was a culture amongst some people that this should not be done and that no more glyphs for ligatures should be added to regular Unicode, and that ligature glyphs should be unmapped within a font and only be accessible using glyph substitution technology. The ligature glyphs in U+FB00 to U+FB06 only being included in Unicode for backward compatibility with some prior standard.
I thought that this missed out the very real fact that people using non-OpenType-aware software packages could not access ligature glyphs to produce printouts, so I decided to produce some code point allocations for ligature glyphs within the Unicode Private Use Area.
http://www.unicode.org/mail-arch/unicode-ml/y2002-m05/0223.html
Doug Ewell wrote as follows.
http://www.unicode.org/mail-arch/unicode-ml/y2002-m06/0422.html
The following two posts are from James Kass, the producer of the Code2000 font.
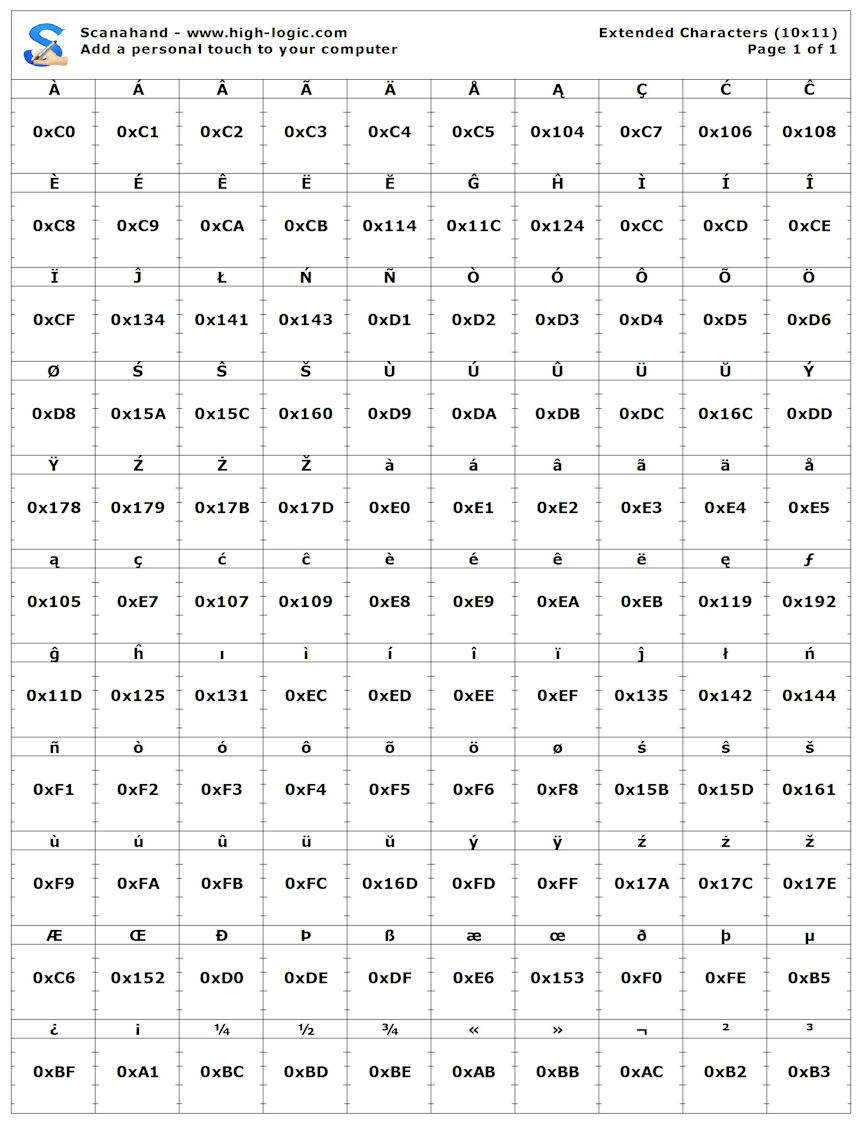
When I tried the range 59143-59252 I expected it to have all blank cells. I was amazed that there were any glyphs shown at all! Also I was reminded of the phrase “I laughed out loud” in the following post.
When I had looked at the English example and at the example which Bhikkhu Pesala posted, I had not realized that the Code2000 font was being used. So, it was with amazement that I saw the ct ligature glyph in the top left cell of the pdf which the system produced for me! Similar perhaps to when James Kass saw the ct ligature in the Unicode mailing list post from Doug Ewell in 2002.
Although those posts all happened in 2002 it seems to me that the use of Private Use Area codepoints for glyphs for ligatures is still needed in 2008, perhaps more needed now because there is, because of OpenType technology, more interest in glyphs for ligatures yet people without the very expensive packages cannot display them nor print them!
The following blog from Thomas Phinney may also be of interest to readers.
http://blogs.adobe.com/typblography/2006/05/eliminate_priva.html
Well, that is, in my opinion, a benefit and not a defect. Please do not change it.
Well, “quick” only because of your skill and ability to produce such excellent results. I would not be able to produce it in a month!
It is not “dirty”. In my opinion, it is a great step forward.
I have thought of a few matters that I would like to mention. Could you possibly consider making the inclusion of the guidelines across the cell an option please and making the glyph in the cell an option too please. People using black and white printers might get problems with scans having unwanted dark pieces in them.
Also, in Unicode, U+FFFE and U+FFFF (65534 and 65535) are non-characters. Could it be a useful convention that if someone uses 65535 in one of your templates that Scanahand then uses that glyph for the .notdef glyph of the font?
William Overington
13 August 2008