Bhikkhu Pesala wrote:...Anyone making multi-lingual fonts should be using FontCreator, not Scanahand...
I think Scanahand could be wonderful tool for as well hobbyist as professional. There seems not to be Scanahand like tool in the market, which "is full of" manual scan and trace glyph per glyph tools. These include professional softwares like Fontlab, Typetool, Scanfont and as I can see also Fontographer. FontCreator is also this like tool, with lack of automatic font generation using glyph templates. So with FontCreator it is hard work to make multi-lingual fonts.
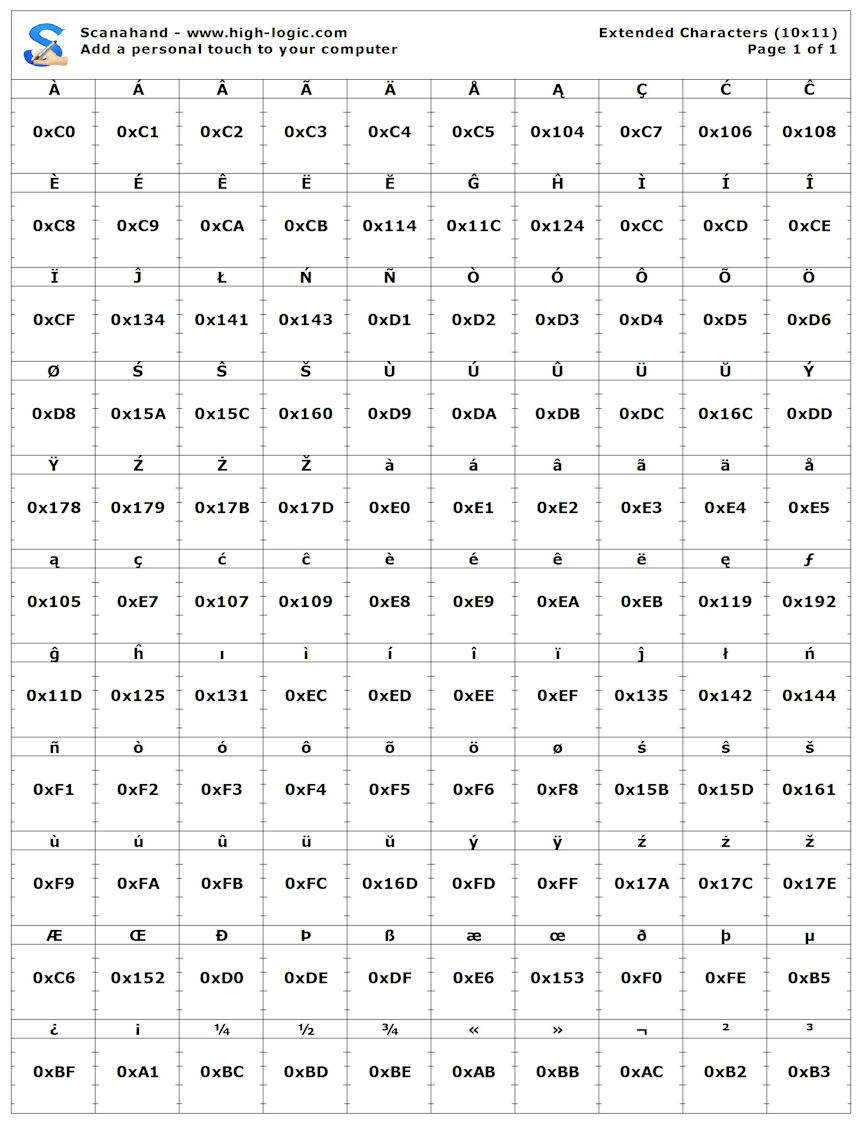
Now we have one page template in Scanahand (Basic). Why should we restrict it's possibilities to two page template and waste our time to think what glyphs to include in the second page?
Reasonable would be allow all characters in unicode, at least Basic Multilingual Plane (BMP) 000000..00FFFF (65536 glyphs). In practice there are only few font creators who needs these all in one font. Fonts has nearly always only some subset of unicode and nearly always only some subset of unicode blocks. For example Verdana covers the following 18 unicode blocks, but NONE of them inlcude all possible characters of the block. As we can see, Verdana has only 95 characters of 128 Basic Latin characters.
Basic Latin (95 of 128)
Latin-1 Supplement (96 of 128)
Latin Extended-A (128 of 128)
Latin Extended-B (11 of 208)
Spacing Modifier Letters (9 of 80)
Combining Diacritical Marks (5 of 112)
Greek and Coptic (73 of 127)
Cyrillic (94 of 255)
Latin Extended Additional (96 of 246)
General Punctuation (23 of 106)
Superscripts and Subscripts (1 of 34)
Currency Symbols (5 of 22)
Letterlike Symbols (6 of 79)
Number Forms (4 of 50)
Mathematical Operators (14 of 256)
Geometric Shapes (6 of 96)
Private Use Area (12 of 6400)
Alphabetic Presentation Forms (2 of 58)
The questions are:
1) in which criteria to select unicode blocks to the new font
2) in which criteria to select what characters to include from these blocks to the new font
Some reason there must be that the creator of Verdana has included only 21.7 % of general punctuation marks. Maybe he/she has thought that some chars are more essential or widely used than others.
One way to answer this is statistical way: to collect widely used fonts, calculate what blocks and portions of blocks are most common and use these results as the base for own font templates.
The technic that allows free selection of unicode ranges is simple. In the Scanahand the must be one embedded font that covers the whole unicode plane. At the beginning the Basic Multilingual Plane (BMP) 000000..00FFFF (65536 glyphs) is enough. Scanahand uses this font to print sample characters in the template pages.
If the program would use fixed page unicode ranges then the program would always know how to map the glyphs. But if we go to the dynamic user created glyph templates (which is really preferable), the solution is little more complicated.
When there is 1-10 dynamically created template pages, there must be some way to include the information of the page unicode ranges to the printable template page - without this page-related information it's in practice not possible to map scanned glyphs to unicode mapping slots.
One of the best solutions is Data Matrix Barcode, which can include thousands of bytes information to small image. When the Matrix image that has encoded information of page's character range is printed on the top of the page then Scanahand can decode the information back to the character range. Data Matrix has built-in error correction, so it is very tolerant to image noise (scan dust & scratches, misaligned lines in print etc.).
EDIT: Of course, I don't mean that the fixed two page template is to be removed. I mean it's not enough. So the user should have ability to select between fixed template(s) and dynamic template. The average user could select one of the fixed templates (or default template) and the advanced user could select one of the fixed templates and modify unicode ranges of it and use that modified dynamic template.