Hi,
I am having a problem with the “Complete Composites” command. The minuscule letter vowels work fine witht he “complete composite” command but the capital letters do not seem to work. The glyphs for the capital letters are copied into the composite respective cells but the diacritic marks are not. Does anyone know why this is so? In the previous FC 5.6 version they both worked fine.
Thanks for your help.
If you can attach the font we will probably find the answer a lot quicker.
So, did you solve this problem?
No I did not solve the problem. I concluded that it was best to copy the diacritics and the letters from the root glyphs. The reason was aldo due tot he fact that the diacritics in most cases required alignment with the slanting of the cursive script and also the diacritic glyph for the Capitals was too large for the minuscule letters, as in this cursive the difference between x-height and Capital line is more pronounced than is the case with a regular non-slanting script. Hence I had no choice but to complete them manually. It did not take me long to complete the diacritic vowels and those few consonants.
What is taking a lot longer is the Autokerning feature. But I will write a separate email on this topic later today. I am just examing how the program behaves with this feature. A limitation seems to be that it uses a 7-bit buffer hence the maximum amount of glyphs that can be entered in one go is limited to 128. But I am trying to establish whether this is per operation or all altogether. In some cases the number of permutation performed by the Autokerning feature does not correspond to the theoretical number of permutations calculated mathematically. I have noticed that some sequences are broken up. For example I did a trial to autokern the minuscule letters a and b with the 10 digits 0 to 9. The reuslt was: a0, a1, a2, a7, a8, a9; then b1, b2, b3, b4, b5, b6, b7, b8, b9. The missing chain a3 to a6 could not be seen anywhere in the result list.
I will write a note later on this subject once I am more certain how this program feature behaves.
Cheers
If the accents are not being generated automatically, perhaps the mappings are incorrect, or there is some other problem I don’t know about. If you can attach the font, then I can see what the problem is.
If you use simple glyphs you will lose all the benefits of using composites (easier editing, smaller file size, etc.)
If you need different accents for lowercase/uppercase, this can be achieved automatically by creating low profile diacritics for uppercase in the Private Use Area.
The design is up to you — I call them low-profile because they are designed to save space above capital letters, but they could be bigger then regular (lowercase) accents if that’s what your design requires.
Thanks for your reply which, a usual, is exhaustive in information and welcome. I feel that with every thread I get from you I am edging closer to becoming a top typographer. Jokes apart, Bhikkhu, the mappings are correct because they worked for the minuscule letters but not for the majuscules. There is probably some other issue but it is not really worth pursuing as because of the discovery that I needed a lower profile diacritic set, as you appropriately define them, I resolved that it was easier to just adjust those that fitted the minuscule letters for the Capitals by resizing then manually once and then do some copy and paste and positioning by hand. It took about 20 minutes to perform this task.
Thanks again for your answer.
The word Majiscule is misspelt. can someone please correct it to majuscule? I do not know how to do it.
This problem has come up again. I am working on the Cursive Testfont for the VOLT thread and again I am not able to complete the majuscule composites. The minuscule are fine and also the majuscule A composites are fine. But the others just do not work. What happens is that the correct capital letter is pulled up but instead of the diacritic mark this time I am getting a glyph from the Private Use Area! You can see this better in the enclosed file of the font set.
As you can see from the table if I try to complete the composite E grave I just get the letter E and the letter v as a diacritic from the Private Use Area of the table. If I try the E acute I gate the letter E and the letter w from the private Use Area.
Table mappings seem all correct. Likewise the range seems correct.
I have run FC both under Windows 7 and 8 and the behaviour is identical.
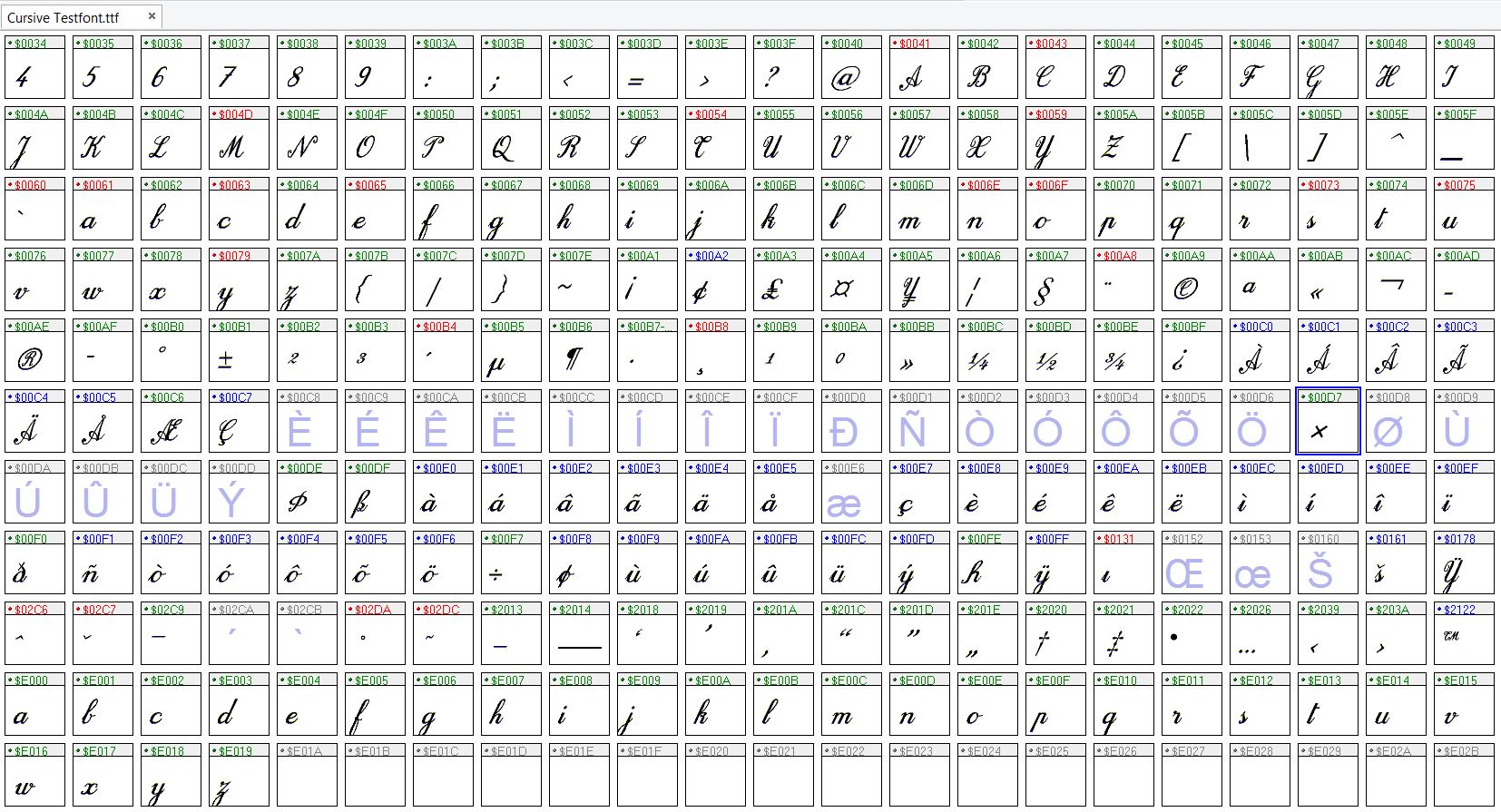
The Low Profile diacritics cannot be placed just anywhere in the Private Use Area. The Complete Composite feature expects to find them at specific code-points (57365-57376 decimal).
Low profile grave is at $E015
Low profile acute is at $E016
Low profile circumflex is at $E017
Low profile caron is at $E018
Low profile tilde is at $E019
The Low Profile Glyph Transform script will insert the characters to the correct code-point if they are not already used by other glyphs in the PUA.
<?xml version="1.0" encoding="ISO-8859-1"?>
<DATA>
<TransformScript>
<OtherComments>
<Content>Low Profile Diacritics
This script inserts low profile diacritics designed for use with uppercase composites.
They need to be edited manually to reduce their vertical size to about 70% but they should retain the same weight. Although they are only used with uppercase, they should be positioned vertically for lowercase. FontCreator will move them up for uppercase, the same as it does with regular accents.</Content>
</OtherComments>
<GlyphInsertCharacters>
<Characters>57365-57376</Characters>
<OverrideRange>TRUE</OverrideRange>
</GlyphInsertCharacters>
<GlyphCompleteComposites>
</GlyphCompleteComposites>
<GlyphDecompose>
</GlyphDecompose>
<MetricsWidth>
<WidthType>0</WidthType>
<Width>1024</Width>
<Adjust>0</Adjust>
</MetricsWidth>
<MetricsCenterGlyph>
</MetricsCenterGlyph>
<MetricsLeftSideBearing>
</MetricsLeftSideBearing>
</TransformScript>
</DATA>
There is no way for FontCreator to guess where users will map extra glyphs in the PUA, or what postscript names they will use, or what glyph index they will have. Therefore, the CompleteComposites.xml data file maps a wide range of codepoints in the PUA for the use of Glyph Transform scripts to insert Stacking Diacritics, Low Profile Diacritics, Petite Capitals, Ligatures, etc.
Please read the documentation already pointed out for more details.
The thread title is too long to edit to correct the typo, so I have shortened it.
Thanks for the input which has now been read and reasonably understood after a first reading. Let me just point out, however, that these detailed pieces of information should be located in the manual pdf file rather than in different threads dispersed in the High Logic forum or fora. One assumes that the Private Use Area is what is says it is and not that the first 20 character mappings of that areas have been reserved for a specific complete composite functionality required by Font Creator and added as an extra xml file. If the manual does not say so than the user cannot be assumed to know as you cannot assume that he or she will go and ask the forum.
The manual should remain the reference for all these detailed pieces of information and exceptions.
Anyway thanks for the input. But I have another question: are there any other exceptions in the PUA? Where should I place the alternative set of minuscule glyphs?
The information is in the help file, but one can often learn a lot quicker by reading menus and dialogues carefully. Support fora are invaluable for getting up and running more quickly with any software. I don’t think it pays to invest too many resources into writing comprehensive help files that only a few people will read from cover to cover.
See the section on using the Glyph Transformer, with a cross-reference to the Tutorials. This link and the same information is found on page 94 of the PDF manual.
I find online tutorials a huge help when providing support, and Serif™ software have now followed this route with my encouragement from seeing how well it works for High-Logic products.
Alternate Glyphs for OpenType features don’t actually need to be mapped at all, as they can be accessed with just postscript names. If you look at most Pro fonts the extra glyphs are not mapped at all, but the Transform scripts and Complete Composite features need to use glyph mappings.
The Using Glyph Transformation tutorial lists these code-points that are used for Petite Capitals corresponding to these Character Sets.
58033-58126 Basic Latin
58160-58255 Latin-1 Supplement
58256-58383 Latin Extended-A
58384-58591 Latin Extended-B
58912-58974 Basic Greek
59072-59218 Cyrillic
59680-59829 Latin Extended Additional
60531-60542 Number Forms, Nut Fractions or Stacking Fractions
Then there are:
61124-61392 Discretionary Ligatures
60600- 60664 Stacking Fractions, and
60065-60090, 60096-60122, 60180, 60200, 60218, 60232, 60250 Ordinals
The Low Profile code-points don’t seem to be listed, so the tutorial needs updating to be more comprehensive.
Perhaps future versions of FontCreator can find another solution that uses postscript names, but we would still have the same problem of making sure that users know the right postscript names to employ. There are no standards to follow that I know of — each type foundry will have their own methodology. Even the Unicode standard is still evolving with new code-points being assigned for newly supported languages and character sets.
I have added an appendix to the PDF version of the tutorial for Working With Glyph Transformations, which summarises the code-points in the Private Use Area used Complete Composites and Glyph Transformation scripts.
Fine I understand now and thank you for your helpful inputs.