I had a problem with the Hungarian fonts, the letters őŐ and űŰ. I use Glyph Transformer to generate the Eastern European letters, but it always generates the long accent in the wrong place for both upper and lower case letters. I suppose it puts the doubleacutemod ($02DD) character over the letter, but the position is almost never right, even though this letter is similar to the letters óÓ and úÚ.
In some letters, the accents are replaced by a completely different glyph.
How can I modify the script to get the accents in the right place after generation?
There were letters where the accent disappeared at the capital letter when using Auto Composite.
Here is the full set of Hungarian accented letters for testing, and I attached a sample for good positions:
árvíztűrő tükörfúrógép ÁRVÍZTŰRŐ TÜKÖRFÚRÓGÉP
This places the double acute combining diacritical mark (779 decimal code-point) offset to the right of the centreline of the base glyph, by one third of the width of the accent. It is the same as that for the single acute accent.
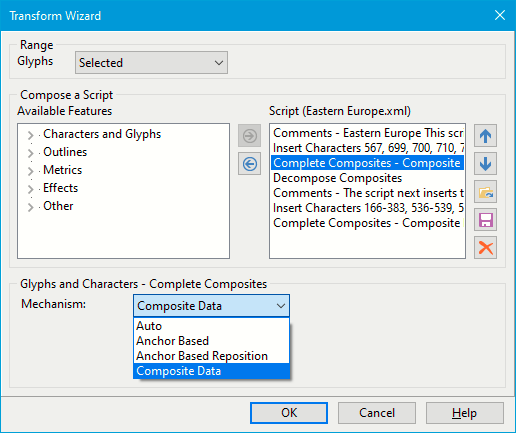
Recent versions of FontCreator 12 to 14 have the option to use Anchored-based glyph positioning, which may give better results.
The Eastern Europe Glyph Transform script still uses the old method, but it can be edited to use Anchored-based positioning. Disappearing Letters
If any composites disappear after using Complete Composites, your font is missing one or more of the required composite glyph members, or they are incorrectly named. Generate glyph names to make sure that they are correct.
Thanks for the great ideas, I will try it and get back to you! I am currently using the latest version 14 and will definitely try anchor based positioning.
It seems to be font dependent. For Jangkar the Composite or Auto setting works, but for capital letters the accent is missing, the script runs badly.
I tried other fonts, but unfortunately none of the Anchor alignments gave good results.
There were some fonts where the doubleacutemod was generated empty, so the Hungarian accented letters were not generated correctly (e.g. Lady Suettaya font, see attachment). In such cases, what step should be taken before the script runs?
Anchor based positioning works with combining marks. In this case is uses doubleacutecomb and has code-point $30B. This accent is also known as Hungarian umlaut or hungarumlautcomb.
Use combining diacritics for composite accents. If they do not exist in a font, you will need to add them.
CompositeData.xml will generate combining accents, if they do not exist, from modifier accents (if they do exist). Glyph doubleacutcomb is code-point 779 (decimal).
If you need smaller or more acute accents for uppercase, add them using the correct names, e.g. doubleacutecomb.case. They don’t need to be mapped, but they do need to be correctly named.
The letters may not have been made by professionals, but I’ll show you some interesting facts about the letter Jangkar.
If I use Anchor settings, this will be the final result:
If I run the script with Composite data setting, the accents appear, but then they are slipped, high up, missing in the capital letters.
How can I put the Hungarian accents in relative position if the original letters have no anchor?
Ok, there is no anchor in the font for any letter. This is a TTF file. I’ve looked at the help and the videos, but it’s not clear yet when and where to insert an anchor. Should I anchor each character one by one and then run the script, or should I insert a doubleacutcomb character first, set it up, anchor it and then run the script?
If I choose the Anchor Based composite, why don’t the letters appear, only their positions? Do those letters need to be anchored as well?
Add the required accents first, then complete anchor-based composites.
The anchors will be added automatically. They can be moved later if not in the desired position. Moving an anchor, e.g. over the letter “o” will move all of the accents for o: ö, ò, ó, õ etc.
The tutorial on Diacritical Marks will tell you more. Don’t try to understand everything at once - take one step at a time, and experiment with the font that you are editing.
The anchor positions are saved in the font project and exported in the new font.
If you open a typical Windows font like Arial, you can see that there are many anchors.
I watched your video, but this anchor thing is too much for me.
In principle, the idea would be that I set which is the top point for the capital Ű and the lowercase Ű, for example, and then put the same anchor at the bottom of the doubleacutecomb, and so they are connected there.
But I played around with this all afternoon and evening, still couldn’t figure out the logic. If I switch to simple for the letter, it loses the connection to the doubleacutecomb character, but if auto attach is enabled, I can move the doubleacutecomb character, not the letter. This is understandable if the anchors would meet, but I can’t get them in sync.
It’s really getting easier to manually drag the accent to the four letters and that’s it… The whole anchor thing is complicated for me, plus I have to play with it font by font to get the double accent to fall into place like the other letters.
Plus, I don’t have generated anchors until I run the Eastern Europe script and then switch the alignment to anchor mode, which causes the original accent positions to slip and I have to reset those too.
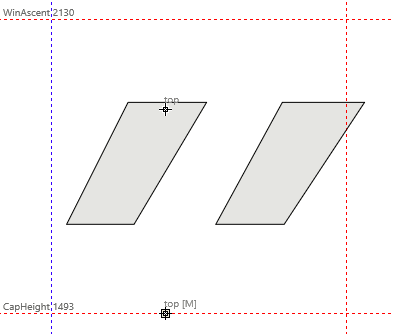
See my anchors in picture: have two toprights and tops (one for the accent, one for the letter), no any connection between them.
In my font, the Top anchor is on the double acute accent. As you can see, it aligns with the CapHeight.
The double acute accent in U double acute cannot be moved, because its positioned is controlled by the anchor auto attachment.
I was largely responsible for editing the CompositeData.xml file, and continued using it long after FontCreator 12 had been released. For positioning of some diacritics, I had to use all kinds of kludges to position accents over some base glyphs, but anchor-based composition is a better solution.
Complete Composites can be used to compose symbols too, e.g. ± from plus and minus, or colon and semicolon from period and comma. It works better for standard text fonts than it does for scripts.
Anchor-based composition should work better for your font.
I might head for CompositeData.xml until I get to grips with the anchors. Many letters do not contain Hungarian characters and I would like to replace them quickly and easily. The script provided a solution to this, only the relative positioning was a problem.
The generation of the doubleacutecomb is not a problem, most of the time it is done well by the program, but the accent is not positioned in the right place, different for each font, I am looking for a solution. For example, it reads the accent positions of the existing accented letters, and inserts the doubleacutecomb character offset based on that. That’s what I was thinking of.
Unfortunately I can’t generate anchors in advance, only after running the script, so there’s little chance to do an anchor-based generation if the letter doesn’t contain an anchor.
It is the Eastern Europe transform script that needs editing. It does not insert all the required accents for the Latin Extended-A character set.
The first part of the script should insert the required combining diacritical marks using Complete Composites to generate the required accents from the glyph modifying accents.
The second part of the script should insert the characters required for European languages
The third part of the script should compose the composite characters in Latin Extended-A etc., using the Anchor-based method
If it is done correctly, the required anchors are added to the base glyphs and accents in all the right places. The vertical or horizontal position of the accents is irrelevant when anchors are used.
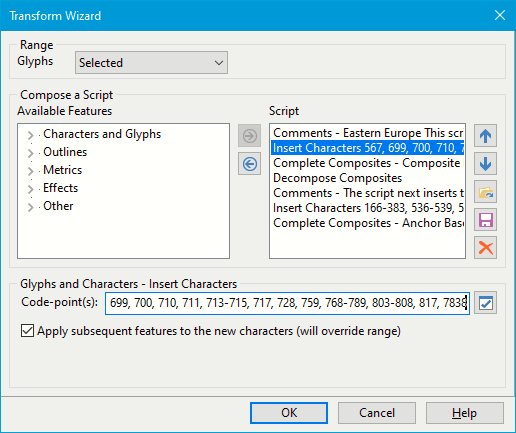
I modified the Glyph Transform script to add combining ogonek, combining cedilla, combining double acute, etc., by editing the first Insert Characters part of the script.
I modified the third part of the script to use Anchor-based Complete Composites instead of CompositeData based composition.
This left a few composites empty, such as Dcroat, but one can just use Complete Composites with CompositeData on those later.
The anchors were added wherever needed, as shown in this example of u double acute.
The TTF font that I started with was an ancient Bitstream font from WordPerfect, which had no anchors, no combining diacritical marks, and no OpenType features apart from kerning, but it did have some of the required glyph modifier accents.
The transform script needs some further refinement, but it does the job well enough for me.
Thank you, I updated my steps above, because after running the script I have to replace the Empty Composite characters first, then the anchor based attachment for all composites, finally the accents are almost perfectly placed with the Auto setting.
I found a trick to restore the accents more accurately. In the Eastern Europe script, you have to put the doubleacutecomb character in the first composite group, and then you get the anchor correctly in the second composite. I have attached the pure Hungarian script, which works for me, and you don’t have to do the multiple composite step afterwards.
If the accents do slip, you must select a Composite Data menu on the Empy characters and they will be restored.
Update1:
I have modified the script (it became Hungarian only.xml). I also added a note, because some fonts are missing the dieresis (code-points: 168) and acomb (code-points: 180) characters.
In such cases, the following steps should be taken:
insert the characters 168 and 180
create the two new characters
run the Hungarian only.xml script
select them all in the Composite group and select Composite Data
Select all in Composite group and Anchor Based
change the position of the acutecomb, doubleacutecomb and doubleacutemod if necessary Hungarian only.xml (946 Bytes)